
.svg)
.svg)


Volljurist und Compliance-Experte

05 Jan 2026

5 Minuten

.svg)
Der EU AI Act verlangt einen lückenlosen Nachweis der Datenherkunft für Hochrisiko-KI.
Fehlende Datenprovenienz macht selbst leistungsstarke KI rechtlich angreifbar.
Fehlende Datenprovenienz macht selbst leistungsstarke KI rechtlich angreifbar.
Gute Datenprovenienz verbessert nicht nur Compliance, sondern auch die Modellqualität.
Stellen Sie sich vor, Sie kaufen einen hochwertigen Gebrauchtwagen. Der Händler versichert Ihnen, dass alles in Ordnung ist. Doch im Handschuhfach fehlt das Scheckheft, und niemand kann Ihnen sagen, wo das Auto die letzten drei Jahre war oder ob es einen Unfall hatte. Würden Sie diesem Auto Ihre Familie anvertrauen?
Wahrscheinlich nicht.
Doch genau dieses Risiko gehen Unternehmen täglich ein, wenn sie Künstliche Intelligenz entwickeln oder einsetzen. Sie trainieren Modelle mit riesigen Datensätzen, deren Ursprung oft im Dunkeln liegt. Solange das Modell funktioniert, fragt niemand nach. Doch mit dem Inkrafttreten des EU AI Act ändert sich diese Spielregeln grundlegend.
Es reicht nicht mehr, dass eine KI „funktioniert“. Sie müssen beweisen können, womit sie gefüttert wurde.
In diesem Artikel tauchen wir tief in das Thema Datenprovenienz (Data Provenance) ein. Wir zeigen Ihnen, warum der bloße Kaufvertrag für Daten nicht mehr ausreicht und wie Sie Licht in die „Black Box“ Ihrer KI-Lieferkette bringen – nicht nur, um Bußgelder zu vermeiden, sondern um bessere, fairere und robustere Systeme zu bauen.
Bevor wir in die technische Umsetzung springen, müssen wir ein gemeinsames Verständnis schaffen. In der Welt der Compliance und Data Science wird oft mit Begriffen jongliert, die ähnlich klingen, aber unterschiedliche juristische Konsequenzen haben.
Datenprovenienz (oder der Nachweis der Datenherkunft) ist im Grunde der Lebenslauf eines Datensatzes. Es geht nicht nur darum zu wissen, dass Sie Daten besitzen, sondern die gesamte Historie lückenlos nachvollziehen zu können:
Dies unterscheidet sich von der reinen Data Lineage, die oft nur den technischen Fluss innerhalb Ihrer Systeme beschreibt. Provenienz blickt über Ihre Firmengrenzen hinaus zurück in die Lieferkette.
Der EU AI Act setzt, insbesondere für sogenannte Hochrisiko-KI-Systeme, strenge Maßstäbe an die Datenqualität. Artikel 10 (Daten und Datenverwaltung) ist hier der entscheidende Hebel. Der Gesetzgeber fordert, dass Trainings-, Validierungs- und Testdatensätze:
Das Problem: Wie wollen Sie garantieren, dass ein Datensatz „repräsentativ“ und „fehlerfrei“ ist, wenn Sie nicht wissen, wie er entstanden ist? Ohne einen lückenlosen Nachweis der Herkunft ist die AI-Datenqualität kaum zu belegen. Ein Datensatz, der über fünf Ecken von einem Drittanbieter gekauft wurde, könnte bereits veraltete Informationen enthalten oder unzulässige Bias (Verzerrungen) aufweisen, die Sie ohne Provenienz-Check nie entdecken würden.
In der idealen Welt sammeln Unternehmen ihre Daten selbst. In der Realität sieht es anders aus: KI-Entwicklung ist heute ein riesiges Ökosystem aus Drittanbietern.
Jeder dieser Übergabepunkte ist ein potenzielles Risiko für die Integrität Ihrer Daten. Wenn Sie Daten von einem Broker kaufen, erhalten Sie oft das fertige Produkt, aber selten die "Zutatenliste".
Hier entstehen die eigentlichen Lieferkettenrisiken. Ähnlich wie wir es aus der IT-Sicherheit kennen, wo eine unsichere Komponente das ganze System gefährden kann, kann ein „vergifteter“ oder rechtlich fragwürdiger Datensatz Ihr gesamtes KI-Modell illegitim machen. Der AI Act verlangt faktisch eine Due Diligence für Daten, die viele Unternehmen bisher nur für Finanztransaktionen kannten.
Wie können Unternehmen nun den Anforderungen gerecht werden und die "Black Box" öffnen? Es reicht nicht, auf das Beste zu hoffen. Sie benötigen eine Kombination aus vertraglicher Absicherung und technischer Rückverfolgbarkeit.
Bevor ein einziger Byte fließt, müssen die rechtlichen Rahmenbedingungen geklärt sein. Verträge mit Datenlieferanten müssen Klauseln enthalten, die über Standard-Garantien hinausgehen. Fordern Sie Transparenz darüber, woher der Lieferant seine Daten bezieht. Dies ist nicht nur für den AI Act relevant, sondern auch um DSGVO-Konflikte zu vermeiden.
Der spannendste Teil ist die technische Umsetzung. Hier transformieren wir abstrakte Anforderungen in Engineering-Tasks.
Eine robuste Strategie für Hochrisiko KI umfasst oft folgende Schritte:
Um dies greifbar zu machen, haben wir einen Workflow visualisiert, der zeigt, wie Datenprovenienz in der Praxis aussehen kann – vom Einkauf bis zum trainierten Modell.
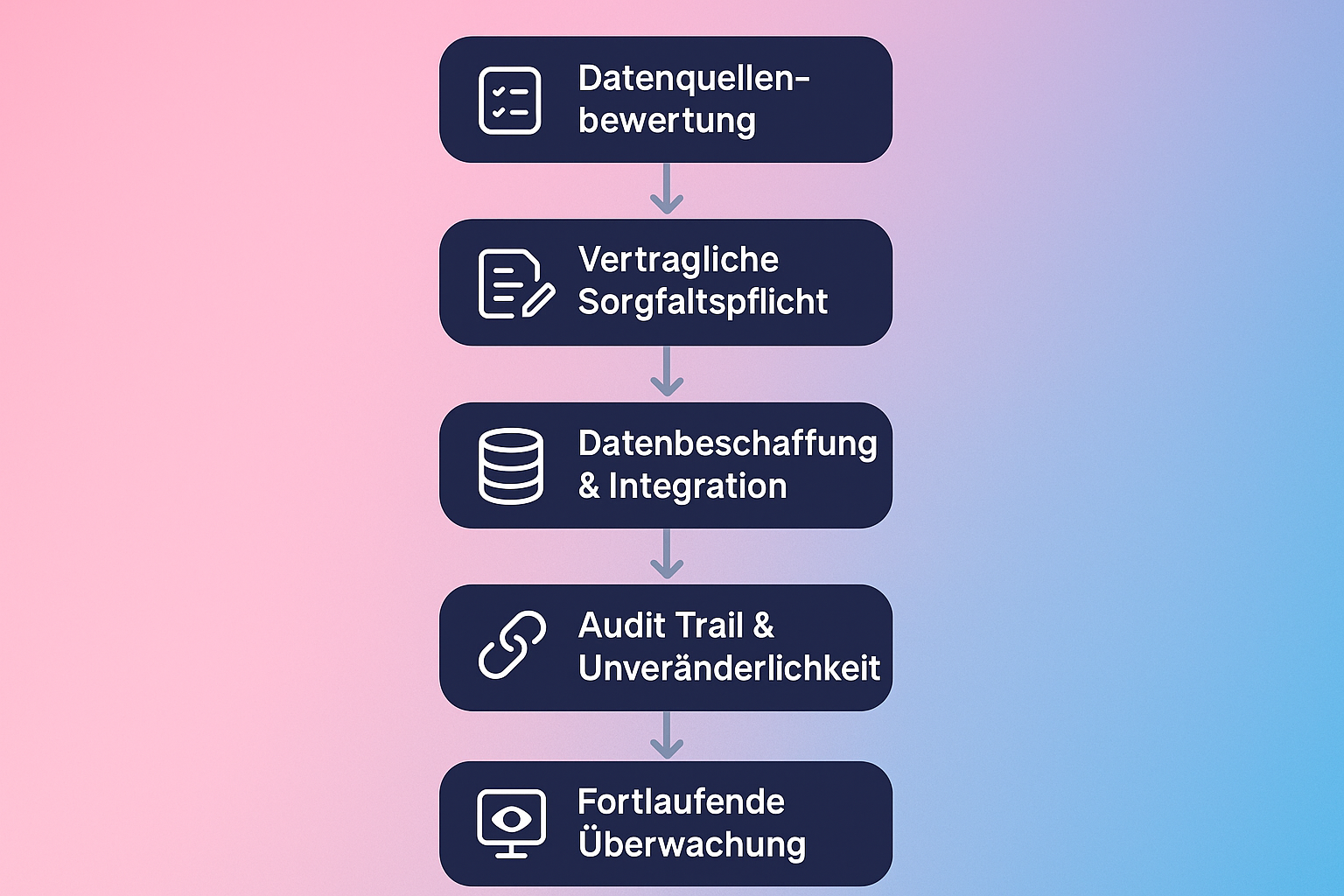
Dieser strukturierte Ansatz hilft nicht nur bei der AI Act Compliance. Er schützt Sie auch vor Haftungsfallen. Denn wenn ein KI-System Schaden anrichtet (z.B. durch Diskriminierung bei der Kreditvergabe), wird die erste Frage der Behörden sein: "Auf welcher Basis hat das System das gelernt?"
Können Sie dann lückenlos belegen, dass Sie alle Sorgfaltspflichten bei der Datenauswahl erfüllt haben, sieht die Situation für die Haftung der Geschäftsführer deutlich besser aus als bei einer "Wir wussten von nichts"-Verteidigung.
Viele Unternehmen sehen Compliance als Bremse. Doch beim Thema Datenherkunft verhält es sich anders: Es ist ein Qualitäts-Booster.
Wenn Sie genau wissen, woher Ihre Daten kommen, können Sie:
Es entsteht eine Synergie: Die Maßnahmen für Datenqualität und AI Act Compliance führen fast automatisch zu leistungsfähigeren und robusteren KI-Produkten.
Der Nachweis der Datenherkunft ist keine rein bürokratische Übung. Er ist das Fundament für vertrauenswürdige KI. In komplexen Lieferketten den Überblick zu behalten, erfordert zwar initialen Aufwand, zahlt sich aber durch Rechtssicherheit und höhere Produktqualität aus.
Unternehmen, die jetzt handeln und Transparenz in ihre Datenströme bringen, werden den AI Act nicht als Hürde, sondern als Qualitätsiegel nutzen können.
Fühlen Sie sich bereit, Ihre Datenlieferkette unter die Lupe zu nehmen? Beginnen Sie nicht mit Technologie, sondern mit einer Bestandsaufnahme: Welche Daten nutzen wir, und woher kommen sie wirklich?
Wenn Sie tiefer in die technische Umsetzung einsteigen wollen oder Unterstützung bei der Automatisierung Ihrer Compliance-Prozesse suchen, lohnt sich ein Blick auf unsere weiteren Ressourcen zum Thema Hochrisiko KI. Compliance muss nicht kompliziert sein – sie muss nur gut organisiert sein.
Ja, auch als Betreiber haben Sie Sorgfaltspflichten. Sie müssen zwar nicht das Modelltraining überwachen, aber sicherstellen, dass der Anbieter Ihnen die Konformität (inklusive Datenhinweise) bestätigt. Ignoranz schützt hier nicht vor Strafe.
Data Lineage beschreibt meist den technischen Weg der Daten innerhalb eines Systems (z.B. von Tabelle A zu Tabelle B). Data Provenance ist umfassender und beinhaltet den Ursprung, die Urheberschaft und die rechtlichen Bedingungen der Datenentstehung, oft über Unternehmensgrenzen hinweg.
Das ist ein häufiges Problem. Für Hochrisiko-KI-Systeme unter dem AI Act können solche Daten ein Risiko darstellen. Eine Risikobewertung ist hier unerlässlich. Oft müssen diese Daten bereinigt oder durch besser dokumentierte Daten ersetzt werden, um die Anforderungen an Fehlerfreiheit und Repräsentativität zu erfüllen.
Nicht zwingend. Blockchain kann helfen, einen manipulationssicheren Audit-Trail zu erstellen, ist aber oft mit hohem Aufwand verbunden. Robuste Metadaten-Management-Systeme und audit-sichere Logs sind für viele Anwendungsfälle ausreichend und einfacher zu implementieren.
Als Jurist mit langjähriger Erfahrung als Anwalt für Datenschutz und IT-Recht kennt Niklas die Antwort auf so gut wie jede Frage im Bereich der digitalen Compliance. Er war in der Vergangenheit unter anderem für Taylor Wessing und Amazon tätig. Als Gründer und Geschäftsführer von SECJUR, lässt Niklas sein Wissen vor allem in die Produktentwicklung unserer Compliance-Automatisierungsplattform einfließen.
SECJUR steht für eine Welt, in der Unternehmen immer compliant sind, aber nie an Compliance denken müssen. Mit dem Digital Compliance Office automatisieren Unternehmen aufwändige Arbeitsschritte und erlangen Compliance-Standards wie DSGVO, ISO 27001 oder TISAX® bis zu 50% schneller.
Automatisieren Sie Ihre Compliance Prozesse mit dem Digital Compliance Office

Die häufigsten Fragen zum Thema

Viele Unternehmen verlassen sich auf die ISO 27001-Zertifizierung ihres Cloud-Anbieters und übersehen dabei ihre eigene Verantwortung. Dieser Leitfaden zeigt, wie Sie den Geltungsbereich Ihres ISMS in IaaS-, PaaS- und SaaS-Umgebungen korrekt definieren, das Shared Responsibility Model verstehen und auditsichere Grenzen ziehen. So schaffen Sie Klarheit über Zuständigkeiten, vermeiden Compliance-Fallen und stärken nachhaltig die Informationssicherheit in Ihrer Cloud-Strategie.

Die meisten Sicherheitsvorfälle beginnen beim Menschen. Wie Security Awareness Mitarbeiter zur ersten Verteidigungslinie macht und wie ein Programm im ISMS aussieht.

Für Kleinunternehmen ist ISO 9001 nicht ein Compliance-Behemoth, sondern ein pragmatisches Managementsystem. Lohnt sich die Zertifizierung?
