
.svg)
.svg)


Volljurist und Compliance-Experte

05 Jan 2026

5 Minuten

.svg)
Synthetische Daten ermöglichen faire KI, auch wenn reale Daten verzerrt sind.
Der EU AI Act macht ausgewogene und repräsentative Trainingsdaten zur Pflicht.
Künstlich erzeugte Daten lösen gleichzeitig Bias- und Datenschutzprobleme.
Künstlich erzeugte Daten lösen gleichzeitig Bias- und Datenschutzprobleme.
Stellen Sie sich vor, Sie entwickeln eine KI für das Gesundheitswesen. Ihr Modell soll Hautveränderungen analysieren, um Krebs frühzeitig zu erkennen. Sie haben Tausende von Bildern gesammelt, alles läuft gut – bis Ihnen auffällt: 90 % Ihrer Daten stammen von Patienten mit heller Hautfarbe.
Das Ergebnis? Ihr Modell wird bei Patienten mit dunklerer Hautfarbe unzuverlässig sein. In der Fachsprache nennt man das „Bias“ (Verzerrung). Unter dem kommenden EU AI Act ist das nicht nur ein technisches Ärgernis, sondern ein Compliance-Risiko, das hohe Strafen nach sich ziehen kann.
Hier stehen viele Unternehmen vor einem Dilemma: Reale Daten sind oft "schmutzig", voreingenommen oder aus Datenschutzgründen (DSGVO) kaum nutzbar. Die Lösung klingt fast zu gut, um wahr zu sein: Daten, die gar nicht echt sind, aber so tun als ob. Willkommen in der Welt der synthetischen Daten.
In diesem Artikel erfahren Sie, wie Sie synthetische Daten nicht nur als Notlösung, sondern als strategischen Hebel für bessere Modelle und rechtssichere Compliance nutzen.
Lassen Sie uns mit einem Missverständnis aufräumen: Synthetische Daten sind keine „Fake News“ für Computer. Es handelt sich um künstlich generierte Informationen, die die statistischen Eigenschaften echter Daten perfekt imitieren, ohne dabei sensible Informationen echter Personen zu enthalten.
Denken Sie an einen Flugsimulator. Ein Pilot lernt dort das Fliegen in einer Umgebung, die sich zu 100 % real anfühlt, aber in der niemand verletzt wird, wenn etwas schiefgeht. Synthetische Daten sind der Flugsimulator für Ihre KI.
Der EU AI Act (insbesondere Artikel 10) stellt strenge Anforderungen an Hochrisiko-KI-Systeme. Die Daten müssen „relevant, repräsentativ, fehlerfrei und vollständig“ sein. Reale Datensätze scheitern oft an drei Hürden:
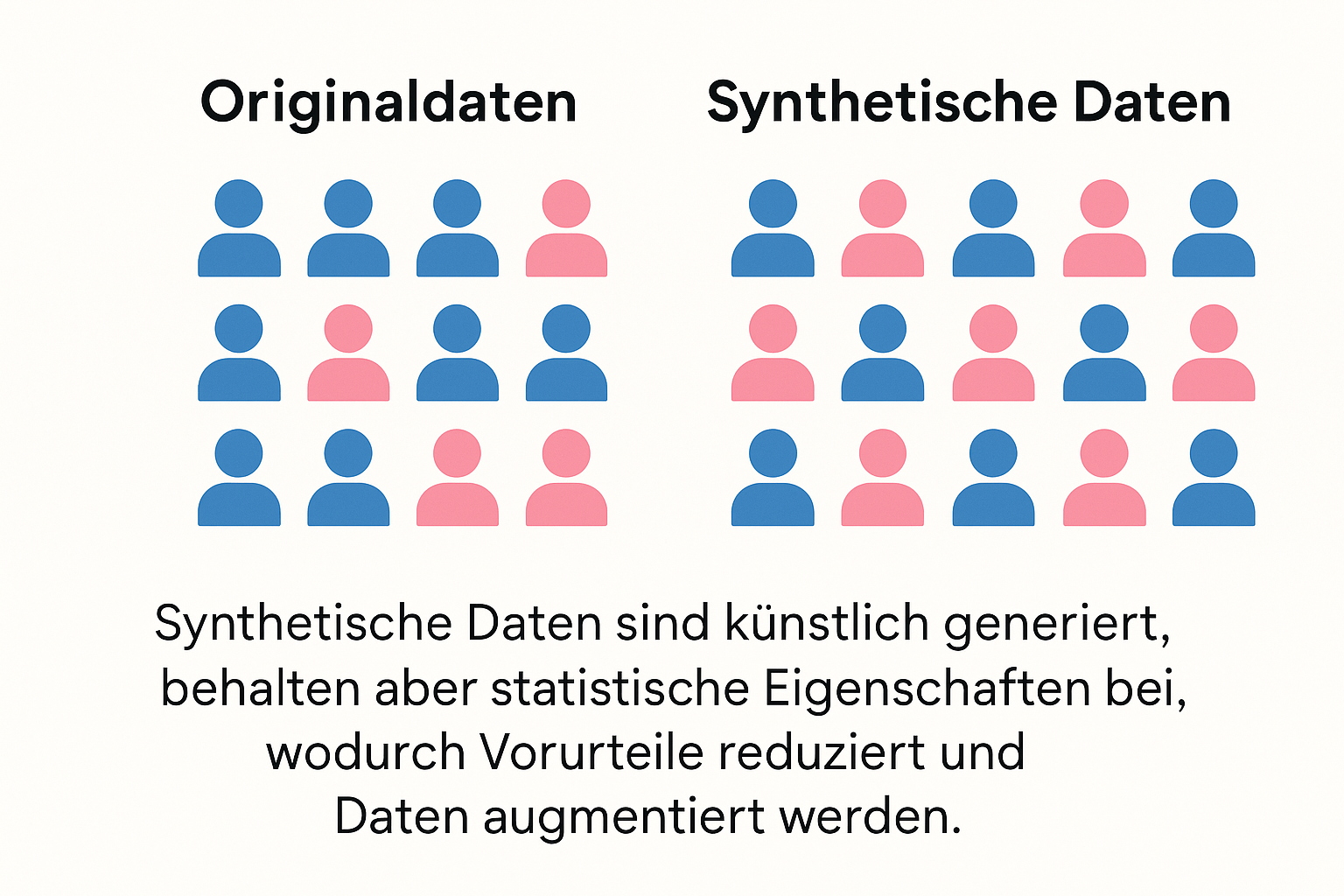
Genau hier greifen synthetische Daten ein. Sie ermöglichen es, die KI-Datenqualität gezielt zu steuern, statt sich auf den Zufall der Realität zu verlassen.
Es reicht nicht, einfach „mehr Daten“ zu generieren. Um Bias aktiv zu mindern und die Anforderungen des AI Acts zu erfüllen, müssen wir die richtige Methode für das richtige Problem wählen. Schauen wir uns die Technik dahinter an – verständlich erklärt.
Dies ist die einfachste Form. Wenn Sie 100 Datensätze von Männern und nur 10 von Frauen haben, analysiert der Computer die statistische Verteilung der Frauen-Gruppe und generiert darauf basierend neue, ähnliche Datensätze.
GANs sind der Goldstandard für realistische Bilder und komplexe Daten. Stellen Sie sich zwei KIs vor, die gegeneinander spielen:
VAEs komprimieren Daten auf ihre wesentlichen Merkmale und rekonstruieren sie dann wieder. Dabei lernen sie die zugrundeliegende Struktur der Daten extrem gut.
Hier werden keine Daten aus bestehenden Daten abgeleitet, sondern eine ganze Welt simuliert (z. B. ein virtueller Straßenverkehr für autonomes Fahren).
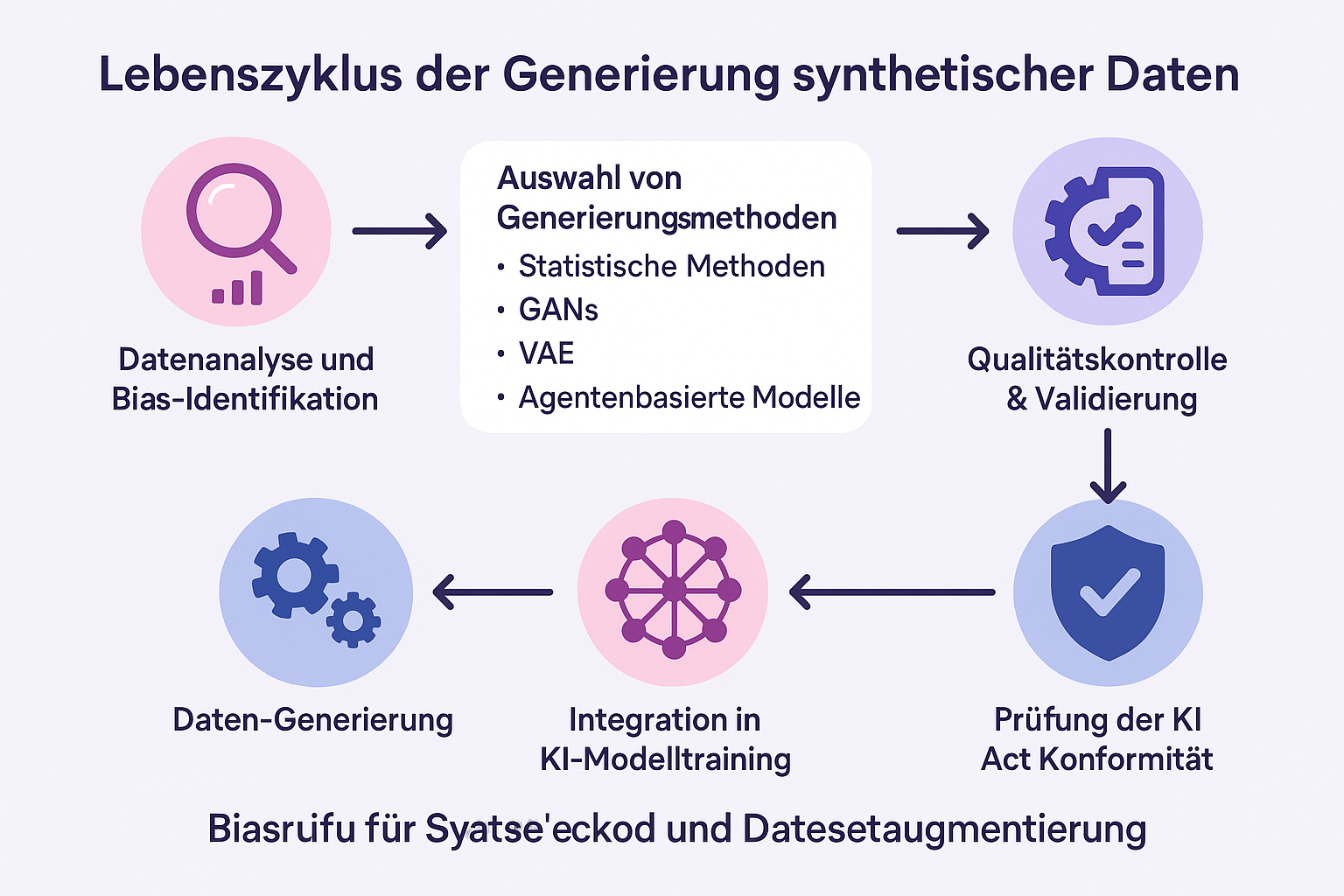
Der EU AI Act verlangt von Anbietern, dass sie KI-Datenqualität verbessern, bevor das Modell auf den Markt kommt. Artikel 10 fordert explizit Maßnahmen zur Erkennung und Korrektur von Verzerrungen.
Wie sieht das konkret aus?
Ein historischer Datensatz zeigt, dass Bewohner bestimmter Postleitzahlen seltener Kredite bekamen. Eine KI würde diesen Bias lernen und Bewohner dieser Gegenden diskriminieren.
Oft scheitert die Compliance nicht am Willen, sondern am Gesetz. Um Bias zu testen, bräuchten Sie oft sensible Daten (Ethnie, Religion), die Sie laut DSGVO gar nicht verarbeiten dürfen.

Synthetische Daten sind mächtig, aber kein Allheilmittel. Es gibt Risiken, die Sie kennen müssen:
Für eine rechtssichere Umsetzung benötigen Unternehmen daher nicht nur Datenwissenschaftler, sondern auch robuste Prozesse für Digital Compliance, die dokumentieren, wie die Daten entstanden sind und wie sie validiert wurden.
Der Einsatz von synthetischen Daten ist weit mehr als ein technischer Trick. Er ist eine strategische Antwort auf die zwei größten Herausforderungen der modernen KI-Entwicklung: Datenknappheit und Regulierung.
Indem Sie Datensätze künstlich erweitern und ausbalancieren, schlagen Sie zwei Fliegen mit einer Klappe: Sie bauen leistungsfähigere, robustere Modelle und erfüllen gleichzeitig die strengen Anforderungen des EU AI Acts an Datenqualität und Fairness.
Der Weg zur Compliance muss nicht steinig sein. Beginnen Sie damit, Ihre Datenstrategie nicht nur aus der Perspektive des "Sammelns", sondern aus der Perspektive des "Generierens" zu betrachten. Wer heute lernt, Datenlücken synthetisch zu schließen, wird morgen die Nase vorn haben – technologisch und rechtlich.
Ja, absolut. Der AI Act ermutigt indirekt sogar dazu, insbesondere wenn es darum geht, Verzerrungen zu korrigieren oder Datenschutzanforderungen zu erfüllen, die mit echten Daten nicht vereinbar wären.
Nicht zwangsläufig. Gut generierte synthetische Daten können die Performance eines KI-Modells sogar steigern, da sie Rauschen reduzieren und fehlende Randbereiche (Edge Cases) auffüllen. Es ist ein Trade-off zwischen „Privacy“ und „Utility“, der gesteuert werden kann.
Dokumentation ist alles. Sie müssen den Generierungsprozess, die verwendeten Methoden (z. B. GANs) und die Qualitätsmetriken (Vergleich der statistischen Verteilung Original vs. Synthetisch) offenlegen. Ein integriertes AI Act Managementsystem hilft hier enorm.
Ja. Wenn der Prozess der Synthetisierung sicherstellt, dass kein Rückschluss auf einzelne natürliche Personen möglich ist, gelten diese Daten nicht mehr als personenbezogen im Sinne der DSGVO. Das befreit Sie von vielen strengen Verarbeitungsgrenzen.
Als Jurist mit langjähriger Erfahrung als Anwalt für Datenschutz und IT-Recht kennt Niklas die Antwort auf so gut wie jede Frage im Bereich der digitalen Compliance. Er war in der Vergangenheit unter anderem für Taylor Wessing und Amazon tätig. Als Gründer und Geschäftsführer von SECJUR, lässt Niklas sein Wissen vor allem in die Produktentwicklung unserer Compliance-Automatisierungsplattform einfließen.
SECJUR steht für eine Welt, in der Unternehmen immer compliant sind, aber nie an Compliance denken müssen. Mit dem Digital Compliance Office automatisieren Unternehmen aufwändige Arbeitsschritte und erlangen Compliance-Standards wie DSGVO, ISO 27001 oder TISAX® bis zu 50% schneller.
Automatisieren Sie Ihre Compliance Prozesse mit dem Digital Compliance Office

Die häufigsten Fragen zum Thema


Das NIS2-Umsetzungsgesetz gilt seit Dezember 2025. Welche Paragraphen Unternehmen kennen müssen, wie die BSI-Registrierung abläuft und warum es keine Übergangsfrist gibt.

Viele KMU fürchten den EU AI Act als neue bürokratische Hürde, dabei bietet er gezielte Erleichterungen und echte Wettbewerbsvorteile. Erfahren Sie, wie Sie Risikoklassen richtig einordnen, regulatorische Sandboxes nutzen und Compliance effizient umsetzen. Dieser Leitfaden zeigt praxisnah, wie Sie den AI Act strategisch für Innovation, Wachstum und Rechtssicherheit einsetzen.
