
.svg)
.svg)


ISO/IEC 27001 Auditorin & QM-Fachexpertin (ISO 9001)

05 May 2026

8 min

.svg)
§30 Abs. 2 Nr. 3 NIS2UmsuCG verpflichtet betroffene Unternehmen zu Business Continuity Management, einschließlich Backup, Wiederherstellung und Krisenmanagement.
Ohne Business Impact Analyse fehlt die Grundlage: Nur wer seine kritischen Prozesse kennt, kann sinnvolle Wiederherstellungsziele (RPO/RTO) festlegen.
Der Notfallplan muss nach NIS2UmsVO Annex 4.1 sieben Pflichtbestandteile enthalten und regelmäßig getestet werden.
Tabletop-Übungen decken in zwei Stunden Lücken auf, die im Alltag nicht auffallen. Wer sein ISMS auf einer Plattform pflegt, dokumentiert die Ergebnisse automatisch.
Ein Ransomware-Angriff legt die Produktion lahm. Der zentrale Cloud-Dienst fällt aus. Ein Rechenzentrum wird durch einen Wasserschaden unbrauchbar. In jedem dieser Szenarien entscheidet nicht die Technik allein darüber, wie schnell ein Unternehmen wieder arbeitsfähig ist. Es entscheidet der Notfallplan, und ob ihn jemand kennt.
Das NIS2UmsuCG macht Business Continuity Management (BCM) zur gesetzlichen Pflicht. §30 Abs. 2 Nr. 3 BSIG verlangt von betroffenen Unternehmen Maßnahmen zur "Aufrechterhaltung des Betriebs", konkret: Backup-Management, Wiederherstellung nach einem Notfall und Krisenmanagement. Dieser Artikel zeigt, wie Unternehmen diese Anforderung von der Pflicht zur funktionierenden Praxis bringen.
§30 Abs. 2 Nr. 3 BSIG nennt drei Säulen der Betriebskontinuität: Backup-Management, Wiederherstellung nach einem Notfall und Krisenmanagement. Die NIS2UmsVO konkretisiert diese Anforderung in Annex 4.1 mit einem detaillierten Anforderungskatalog für Notfallpläne.
In der Praxis heißt das: Ein Unternehmen muss nicht nur Backups erstellen, sondern einen durchdachten Plan haben, der beschreibt, was bei einem Vorfall passiert, wer welche Entscheidungen trifft und wie der Betrieb wiederhergestellt wird. Die Geschäftsleitung trägt persönliche Verantwortung dafür, dass dieser Plan existiert und funktioniert.
Die vollständige Liste der zehn Maßnahmenbereiche nach §30 behandeln wir im Überblick zu den NIS2-Anforderungen. Dieser Artikel konzentriert sich auf den BCM-Baustein und wie er praktisch umgesetzt wird.
Der Ausgangspunkt jedes Notfallplans ist die Business Impact Analysis (BIA). Darin werden geschäftskritische Prozesse identifiziert und bewertet: Welche Systeme und Prozesse sind für die Geschäftstätigkeit unverzichtbar? Welche Auswirkungen hat der Ausfall? Wie lange kann ein Ausfallfall akzeptiert werden?
Die BIA ist mehr als eine IT-Aufgabe. Der CIO sitzt nicht allein im Zimmer und rät, was kritisch ist. Die Geschäftsbereiche (Produktion, Vertrieb, Verwaltung, Forschung) müssen ihre eigenen Abhängigkeiten beschreiben. Ein Produktionsausfallfall von einer Stunde kostet anders viel als ein Ausfall der Email für eine Stunde. Die BIA macht diese Unterschiede explizit.
Praktisch hat sich ein Workshop bewährt, in dem die Geschäftsbereiche und die IT zusammensitzen und folgende Fragen durchgehen: 1. Welche Prozesse sind für unser Geschäft unverzichtbar? 2. Wie lange können diese Prozesse ausfallen, bevor es kritisch wird? 3. Welche IT-Systeme unterstützen diese Prozesse? 4. Wie schnell müssen diese Systeme wieder verfügbar sein?
Aus der BIA ergeben sich zwei Kennzahlen, die das Rückgrat jedes Notfallplans bilden. Das Recovery Point Objective (RPO) definiert den maximal akzeptablen Datenverlust. Ein RPO von 4 Stunden bedeutet: Im schlimmsten Fall gehen die Daten der letzten 4 Stunden verloren. Das Recovery Time Objective (RTO) definiert die maximale Ausfallzeit. Ein RTO von 8 Stunden bedeutet: Der Prozess muss innerhalb von 8 Stunden wieder laufen.
Diese Kennzahlen bestimmen die technische Strategie. Ein RPO von 15 Minuten erfordert synchrone Replikation oder sehr häufige Backups. Ein RPO von 24 Stunden kann mit täglichen Backups erreicht werden. Die technischen Details der Backup-Strategie nach NIS2 behandelt der verlinkte Artikel.
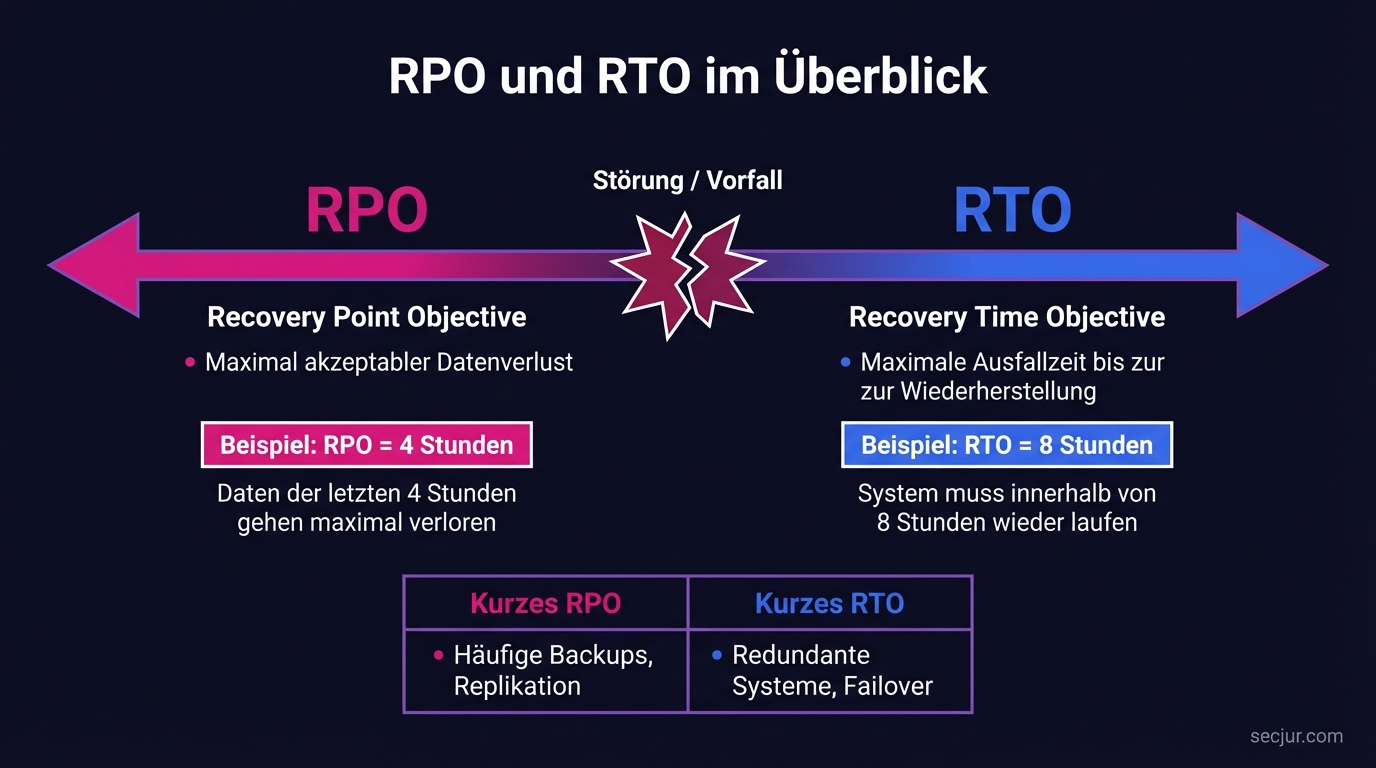
Die BIA liefert die Daten, der Notfallplan ist das Dokument, das aus diesen Daten konkrete Maßnahmen macht. Ein Notfallplan enthält typischerweise folgende Abschnitte:
| Abschnitt | Beispiel |
|---|---|
| Krisenteam | Wer ist Notfall-Koordinator? Wer ist stellvertretender Koordinator? Wer führt den Stab? Welche Kontaktdaten sind hinterlegt? |
| Eskalations- und Meldekette | Wer wird in welcher Reihenfolge informiert? Welche Entscheidungen trifft wer? Wann muss das BSI informiert werden (NIS2-Meldepflicht)? |
| Reaktionsprozeduren | Wenn System X ausfällt: Schritt 1, Schritt 2, Schritt 3. Wenn Ransomware erkannt wird: Isolieren, forensische Analyse starten, Backup-Wiederherstellung einleiten. |
| Wiederanlauf | In welcher Reihenfolge werden Systeme wieder hochgefahren? Welche Integrität prüfen wir vor dem Produktivbetrieb? |
| Kommunikation | Wie kommunizieren wir an Kunden, Partner, Öffentlichkeit? Wer spricht öffentlich? Welche Infos sind publik, welche nicht? |
Ein gut dokumentierter Notfallplan ist das Artefakt, das bei einer NIS2-Prüfung vorgezeigt wird. Ohne Notfallplan lässt sich nicht nachweisen, dass §30 Abs. 2 Nr. 3 erfüllt ist.
Der besten Notfallplan hilft nichts, wenn ihn niemand kennt oder wenn er im Ernstfall nicht funktioniert. NIS2 fordert daher regelmäßige Tests. Zwei Formate haben sich etabliert:
Tabletop-Übung
Das Krisenteam sitzt um einen Tisch und diskutiert ein simuliertes Szenario: "Es ist 2 Uhr nachts, der zentrale Server ist down, Email-Verkehr läuft nicht mehr." Der Moderator fragt nach: Wer wird zuerst angerufen? Was ist die erste Entscheidung? Welche Daten brauchen wir? Nach zwei Stunden Diskussion werden Lücken im Notfallplan sichtbar, die vorher nicht aufgefallen wären. Tabletop-Übungen sind zeiteffizient und kostengünstig, und sie sind für NIS2 vollkommen ausreichend.
Full-Scale-Test
Der Notfallplan wird in der Praxis durchgespielt. Der Test kann vollständig sein (alle Systeme tatsächlich runterfahren und neustarten) oder teilweise (simulierte Ausfälle, real durchgespielte Reaktion). Full-Scale-Tests sind aufwändiger, aber besonders wertvoll, weil sie technische Probleme aufdecken, die Tabletop-Tests nicht sichtbar machen (falsche Wiederherstellungsverfahren, fehlende Konfigurationen, Datenbank-Abhängigkeiten).
Die Ergebnisse jedes Tests müssen dokumentiert werden: Welche Mängel wurden identifiziert? Welche Korrekturmaßnahmen sind eingeleitet? Die Dokumentation ist später der Nachweis, dass BCM nicht nur auf dem Papier existiert, sondern tatsächlich gepflegt wird.
Unternehmen, die bereits ein ISO-27001-ISMS haben, werden feststellen, dass BCM keine neuen Anforderungen auf grüner Wiese erzeugt. ISO 27001 fordert in der neuesten Fassung (2022) in Annex A.8.14 ebenfalls einen Plan zur Wiederherstellung nach Störungen. Der §30 Abs. 2 Nr. 3 BSIG konkretisiert diese Anforderung mit zusätzlichem Detaillierungsgrad, insbesondere beim Nachweis regelmäßiger Tests.
Praktisch heißt das: Unternehmen können ihre bestehende ISO-27001-Dokumentation um die NIS2-spezifischen Anforderungen erweitern (Notfallplan, Krisenmanagement, regelmäßige Tests), statt alles von vorn anzufangen.
Ein einfaches Notfallplan-Template kann aus diesen Abschnitten bestehen:
Ein solcher Plan ist nicht glamourös, aber die Vorlage einer solchen Dokumentation bei einer BSI-Prüfung zeigt konkret, dass die Anforderung ernst genommen und nicht nur in der IT-Ecke abgehandelt wurde. Das ist genau das, was die Regulierung mit BCM im §30 BSIG bezweckt.
Bettina Stearn ist zertifizierte ISO/IEC 27001 Auditorin und Beraterin für Datenschutz und Informationssicherheit. Mit mehr als 15 Jahren Erfahrung in Informationssicherheit, Qualitätsmanagement und Datenschutz begleitet sie Organisationen bei der Einführung und Zertifizierung von Managementsystemen nach internationalen Standards. Neben ihrer Spezialisierung auf ISO 27001 und TISAX® verfügt sie über umfangreiche Erfahrung in der Implementierung und Auditierung von Managementsystemen nach ISO 9001 sowie eine Ausbildung zur QM-Fachexpertin (TÜV SÜD). Ihr Fokus liegt auf der sicheren und effizienten Umsetzung regulatorischer Anforderungen – von NIS2 über TISAX® bis hin zur KI-Compliance nach EU-Vorgaben. Dabei verbindet sie technisches Know-how mit strategischem Blick für nachhaltige Sicherheitsstrukturen.
SECJUR steht für eine Welt, in der Unternehmen immer compliant sind, aber nie an Compliance denken müssen. Mit dem Digital Compliance Office automatisieren Unternehmen aufwändige Arbeitsschritte und erlangen Compliance-Standards wie DSGVO, ISO 27001 oder TISAX® bis zu 50% schneller.
Automatisieren Sie Ihre Compliance Prozesse mit dem Digital Compliance Office

Die häufigsten Fragen zum Thema
Ja. §30 Abs. 2 Nr. 3 BSIG verpflichtet besonders wichtige und wichtige Einrichtungen zu Maßnahmen zur Aufrechterhaltung des Betriebs, einschließlich Backup-Management, Wiederherstellung und Krisenmanagement. Die Pflicht gilt seit dem 6. Dezember 2025.
Incident Response konzentriert sich auf die Erkennung und Behebung eines Vorfalls. BCM stellt sicher, dass der Geschäftsbetrieb auch während und nach einem Vorfall weiterläuft. Beide Prozesse greifen ineinander.
Die NIS2UmsVO verlangt regelmäßige Tests und zusätzlich Tests nach wesentlichen Vorfällen oder Änderungen. Gängige Praxis nach BSI 200-4 ist mindestens einmal jährlich.
ISO 22301 deckt die BCM-Anforderungen weitgehend ab, ersetzt aber nicht NIS2-spezifische Pflichten wie Meldepflicht (§32) oder Geschäftsführer-Schulung (§38). In Kombination mit ISO 27001 bildet sie ein solides Fundament.

Was der EU AI Act im Mai 2026 für Unternehmen bedeutet: Risikoklassen-Pyramide, Pflichten pro Akteur, Strafen-Tiers und zwei pragmatische Umsetzungswege (ISO 42001 oder dedizierte Plattform).
Gerade die Überwachung von Mitarbeitern ist immer wieder Gegenstand gerichtlicher Streitigkeiten. Dabei stehen Unternehmen mittlerweile die verschiedensten Möglichkeiten zur Verfügung - von der Überwachung des E-Mail-Verkehrs bis hin zum Anbringen von Videokameras am Arbeitsplatz. Ob die umfassende GPS-Überwachung von Mitarbeitern datenschutzrechtlich zulässig ist, hatte das Verwaltungsgericht Lüneburg zu entscheiden. Wie ging es aus?
Vergleichen Sie TISAX und ISO 27001 für optimale Informationssicherheit und Compliance. Finden Sie den passenden Standard für Ihr Unternehmen.
