
.svg)
.svg)


Volljurist und Compliance-Experte

06 Jan 2026

5 Minuten

.svg)
Manuelle Datenpflege reicht für AI-Act-konforme KI nicht mehr aus.
Automatisierte Datenbereinigung ist die Grundlage für rechtssichere Datenqualität.
Nur kontinuierliche Validierung schützt vor Data Drift und Compliance-Risiken.
Nur kontinuierliche Validierung schützt vor Data Drift und Compliance-Risiken.
Stellen Sie sich vor, Sie möchten einem angehenden Koch beibringen, wie man ein perfektes Risotto zubereitet. Sie geben ihm ein Rezeptbuch, aber jede dritte Seite ist mit Kaffeeflecken unleserlich gemacht, die Mengenangaben sind in drei verschiedenen Maßeinheiten notiert und bei den Zutaten steht statt "Arborio-Reis" manchmal fälschlicherweise "Kieselsteine". Egal wie talentiert der Koch ist – das Ergebnis wird ungenießbar sein.
Genau an diesem Punkt stehen viele Unternehmen heute mit ihrer Künstlichen Intelligenz (KI). Wir trainieren hochkomplexe Algorithmen, füttern sie aber oft mit Daten, die unvollständig, veraltet oder inkonsistent sind. Bisher war das "nur" ein wirtschaftliches Risiko (schlechte Ergebnisse). Mit dem Inkrafttreten des EU AI Acts wird es jedoch zu einer rechtlichen Hürde.
Besonders für Anbieter von Hochrisiko-KI-Systemen ist Datenqualität keine Kür mehr, sondern strenge Pflicht. Doch wie bewältigt man Terabytes an Daten ohne eine Armee von Data Scientists? Die Antwort liegt in der Automatisierung. Lassen Sie uns gemeinsam eintauchen und verstehen, wie moderne Tools die Datenwäsche revolutionieren – und warum das weniger gruselig ist, als es klingt.

Bevor wir über Tools sprechen, müssen wir das "Warum" verstehen. Der Artikel 10 des EU AI Acts legt die Messlatte hoch. Er fordert, dass Trainings-, Validierungs- und Testdatensätze bestimmten Qualitätskriterien entsprechen müssen. Die Daten sollen relevant, repräsentativ, fehlerfrei und vollständig sein.
Das klingt logisch, aber in der Praxis ist "fehlerfrei" ein gigantisches Wort. Studien zeigen, dass Data Scientists oft bis zu 80 % ihrer Zeit nur mit der Vorbereitung und Bereinigung von Daten verbringen. Das ist nicht nur ineffizient, sondern auch fehleranfällig. Wenn ein Mensch manuell Tausende von Zeilen durchgeht, überliest er Fehler. Das ist menschlich, aber im Kontext der EU AI Act Compliance Software und der gesetzlichen Anforderungen ein Risiko.
Vielleicht kennen Sie das: Datenexporte aus dem CRM, zusammengeführt mit Logs aus der IT und einer Prise Marketing-Daten aus Excel-Tabellen. Das Resultat ist oft ein "Datensumpf". Manuelle Bereinigung scheitert hier an drei Faktoren:
Hier kommt der "Aha-Moment": Automatisierung dient nicht nur der Faulheit oder der Kosteneinsparung. Sie ist der einzige Weg, um AI-Datenqualität auf einem Niveau zu garantieren, das einer regulatorischen Prüfung standhält.
Es wirkt fast wie Magie, wenn moderne Tools einen chaotischen Datensatz in Sekundenschnelle ordnen. Aber dahinter stecken klare Prozesse. Automatisierte Validierungstools nutzen oft selbst Machine Learning (ML), um Muster zu erkennen und Anomalien zu identifizieren.
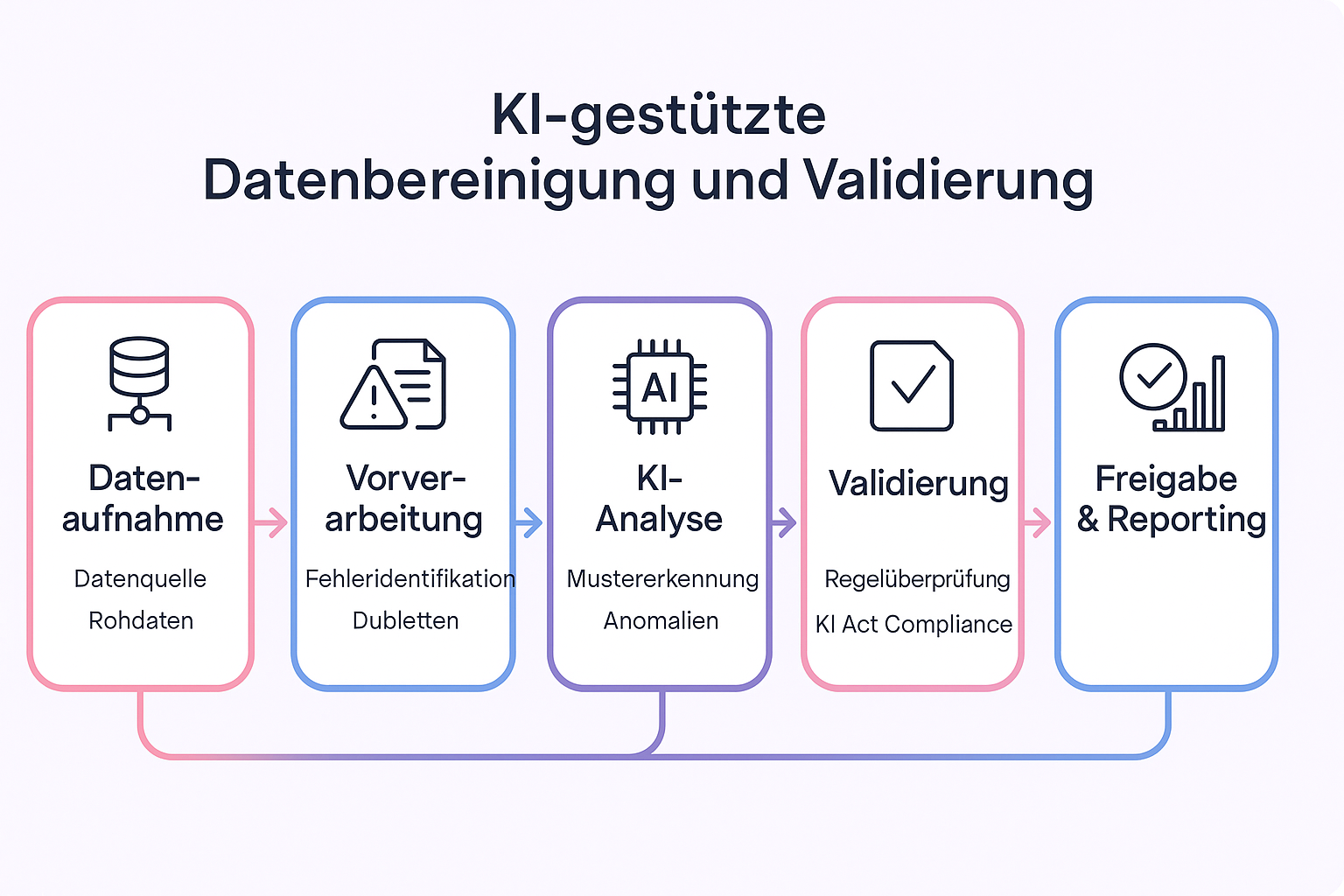
Datenbereinigung ist kein einmaliger Frühjahrsputz. Daten sind fließend. Was heute korrekt ist, kann morgen durch "Data Drift" (die Veränderung der Datenstruktur im Laufe der Zeit) falsch sein.
Automatisierte Validierung bedeutet, dass jeder neue Datenpunkt, der in Ihr System fließt, durch eine Art digitale Schleuse muss. Entspricht er nicht den definierten Qualitätsstandards (Schema-Validierung), wird er gar nicht erst in den Trainingspool gelassen. Dies ist entscheidend, um AI Datenqualität verbessern zu können, ohne den laufenden Betrieb zu stören.
Ein oft übersehener Aspekt ist die Herkunft der Daten. Viele Unternehmen kaufen Daten zu oder nutzen APIs von Drittanbietern. Hier überschneiden sich die Anforderungen des AI Acts oft mit anderen Regularien wie der NIS2-Richtlinie, die ein strenges Risikomanagement fordert.
Wenn Sie Daten von externen Quellen beziehen, müssen Sie sicherstellen, dass diese bereits "sauber" bei Ihnen ankommen oder sofort bereinigt werden. Ein automatisiertes Lieferkettenrisiko-Management hilft dabei, die Qualität externer Datenquellen zu bewerten, bevor diese Ihre KI-Modelle kontaminieren.
Stellen Sie sich vor, eine fehlerhafte Datenlieferung führt dazu, dass Ihr KI-Sicherheitssystem ausfällt oder falsche Entscheidungen trifft. In diesem Fall greift nicht nur der AI Act, sondern unter Umständen auch das Vorfallsmanagement nach NIS2. Sie sehen: Compliance-Frameworks greifen ineinander wie Zahnräder. Saubere Daten sind das Schmieröl für alle diese Prozesse.
Natürlich wirkt der AI Act wie ein strenger Lehrer, der Hausaufgaben kontrolliert. Aber der eigentliche Gewinn liegt woanders. Unternehmen, die automatisierte Datenbereinigung einsetzen, berichten oft von überraschenden Nebeneffekten:
Der Weg zur Compliance führt nicht über mehr manuelle Arbeit, sondern über intelligente Prozesse. Um für den AI Act gerüstet zu sein, sollten Sie sich auf drei Prinzipien konzentrieren:
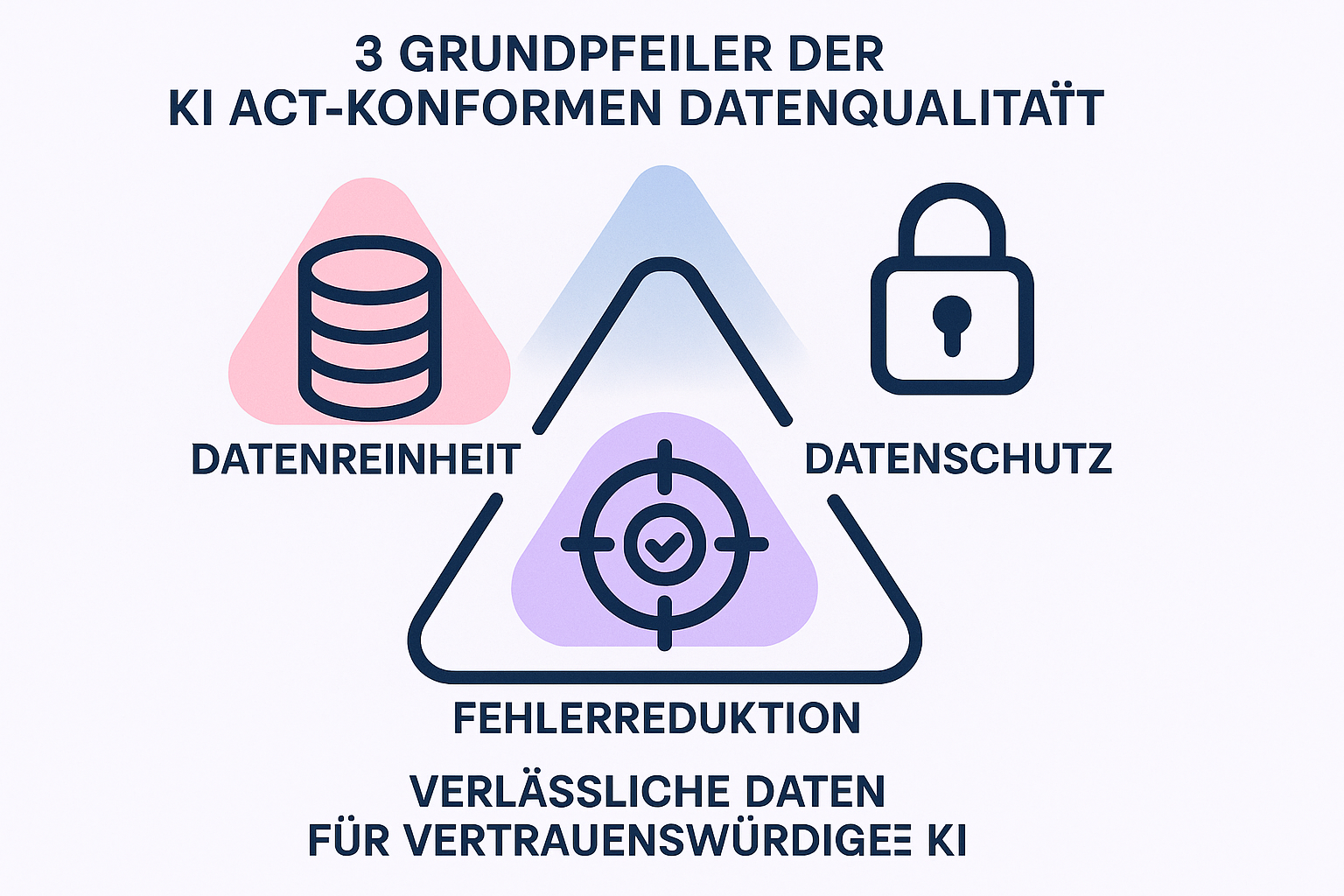
Das Thema Datenqualität mag auf den ersten Blick wie ein trockener technischer Prozess wirken. Doch tatsächlich ist es das Fundament, auf dem Ihre KI-Zukunft steht. Ein automatisiertes System gibt Ihnen nicht nur die Sicherheit, gesetzeskonform zu handeln, sondern befreit Ihr Team von mühsamer Fleißarbeit.
Beginnen Sie damit, Ihre aktuellen Datenquellen zu inventarisieren. Woher kommen Ihre Daten? Wer fasst sie an? Wo passieren die meisten Fehler? Sobald Sie diese Transparenz haben, ist der Schritt zur Automatisierung nur noch klein – und der Weg zu einer complianten und leistungsstarken KI geebnet.
Nein. Der AI Act fordert eine kontinuierliche Überwachung. Zudem verändern sich Daten in der realen Welt ständig ("Data Drift"). Ein Modell, das mit Daten von 2021 trainiert wurde, kann heute völlig falsche Schlüsse ziehen. Automatisierte Tools überwachen diesen Prozess dauerhaft.
Datenbereinigung (Cleansing) ist der Prozess, Fehler zu korrigieren (z.B. ein fehlendes Feld zu füllen). Datenvalidierung ist der Check, ob die Daten den vordefinierten Regeln entsprechen (z.B. "Ist die E-Mail-Adresse gültig?"). Die Validierung findet oft vor der Bereinigung statt, um schlechte Daten gar nicht erst zuzulassen.
Nicht unbedingt. Moderne Compliance- und Data-Governance-Plattformen wie der Digital Compliance Office (DCO) sind oft "No-Code" oder "Low-Code". Sie bieten visuelle Oberflächen (Dashboards), mit denen auch Compliance-Manager ohne IT-Studium die Datenqualität steuern können.
Die strengsten Anforderungen des Artikels 10 gelten für Hochrisiko-KI-Systeme (z.B. im HR-Bereich, Kritische Infrastruktur, Bildung). Aber: Auch für andere KI-Systeme ist gute Datenqualität entscheidend für den Geschäftserfolg und das Vertrauen der Nutzer. Zudem können sich Risikoklassifizierungen ändern.
Als Jurist mit langjähriger Erfahrung als Anwalt für Datenschutz und IT-Recht kennt Niklas die Antwort auf so gut wie jede Frage im Bereich der digitalen Compliance. Er war in der Vergangenheit unter anderem für Taylor Wessing und Amazon tätig. Als Gründer und Geschäftsführer von SECJUR, lässt Niklas sein Wissen vor allem in die Produktentwicklung unserer Compliance-Automatisierungsplattform einfließen.
SECJUR steht für eine Welt, in der Unternehmen immer compliant sind, aber nie an Compliance denken müssen. Mit dem Digital Compliance Office automatisieren Unternehmen aufwändige Arbeitsschritte und erlangen Compliance-Standards wie DSGVO, ISO 27001 oder TISAX® bis zu 50% schneller.
Automatisieren Sie Ihre Compliance Prozesse mit dem Digital Compliance Office

Die häufigsten Fragen zum Thema

NIS1 vs. NIS2 Vergleich: Die wichtigsten Unterschiede zwischen alter und neuer Cybersecurity-Richtlinie für Unternehmen

Viele KI-Projekte scheitern nicht am Modell, sondern an fehlerhaften oder verzerrten Trainingsdaten. Dieser Leitfaden zeigt, wie Sie Datenannotation, Bias-Kontrolle und Qualitätssicherung so aufsetzen, dass Ihre KI den Anforderungen des EU AI Acts entspricht. Erfahren Sie praxisnah, wie strukturierte Guidelines, Human-in-the-Loop-Prozesse und messbare KPIs aus reinen Labels einen rechtskonformen, fairen und auditfesten Datensatz machen.

Werden personenbezogene Daten eines Arbeitnehmers als betroffener Person (vgl. Art. 4 Nr. 1 DSGVO) von dem Arbeitgeber als Verantwortlichem (Art. 4 Nr. 7 DSGVO) verarbeitet, befinden wir uns in einem sehr spezifischen rechtlichen Verhältnis. In dieser Konstellation gilt der sogenannte Arbeitnehmerdatenschutz.
