
.svg)
.svg)


Volljurist und Compliance-Experte

05 Jan 2026

5 Minuten

.svg)
Datenintegrität ist die Grundlage jeder AI-Act-konformen KI.
Ohne technische Nachweise ist Compliance nicht belastbar.
Automatisierte MLOps sichern Daten über den gesamten Lebenszyklus.
Vertrauenswürdige KI entsteht durch kontinuierliche Integritätskontrollen.
Stellen Sie sich vor, Sie bauen ein Haus. Sie verwenden die besten Ziegel, den stärksten Beton und hochwertiges Holz. Doch während der Bauphase tauscht jemand heimlich, in der Dunkelheit der Nacht, zehn Prozent Ihrer Stahlträger gegen billiges Imitat aus. Äußerlich sieht das Haus perfekt aus. Aber beim ersten Sturm stürzt es ein.
In der Welt der Künstlichen Intelligenz ist dies keine Parabel, sondern ein reales Risiko. Man nennt es „Data Poisoning“ oder Datenmanipulation.
Viele Unternehmen konzentrieren sich bei der Vorbereitung auf den EU AI Act ausschließlich auf das fertige Modell oder die Dokumentation. Doch Artikel 10 der Verordnung zielt auf etwas Tieferes ab: das Fundament. Es geht nicht nur darum, dass Ihre Daten zum Zeitpunkt X „sauber“ sind, sondern dass Sie technisch garantieren können, dass sie über den gesamten Lebenszyklus hinweg – vom Training bis zum Betrieb – unverändert und korrekt geblieben sind.
In diesem Beitrag tauchen wir tief in die technischen Ansätze der kontinuierlichen Datenintegritätsprüfung ein. Wir lassen den juristischen Jargon hinter uns und schauen uns an, wie Sie Manipulationen verhindern und Compliance nicht nur behaupten, sondern beweisen können.
Der EU AI Act (KI-Verordnung) ist mehr als eine Checkliste; er ist ein Rahmenwerk für Vertrauen. Speziell für Hochrisiko-KI-Systeme stellt Artikel 10 strenge Anforderungen an die Daten-Governance.
Oft wird dies missverstanden als reine „Datenqualität“ (sind keine Fehler enthalten?). Doch der Gesetzgeber verlangt implizit mehr: Datenintegrität. Das bedeutet, dass die Datensätze für Training, Validierung und Tests nicht manipuliert wurden – weder böswillig durch Angreifer noch versehentlich durch interne Prozesse.
Wenn Sie nicht nachweisen können, woher Ihre Daten kommen, wer sie wann berührt hat und dass sie unverändert sind, stehen Sie im Audit auf wackligem Boden.
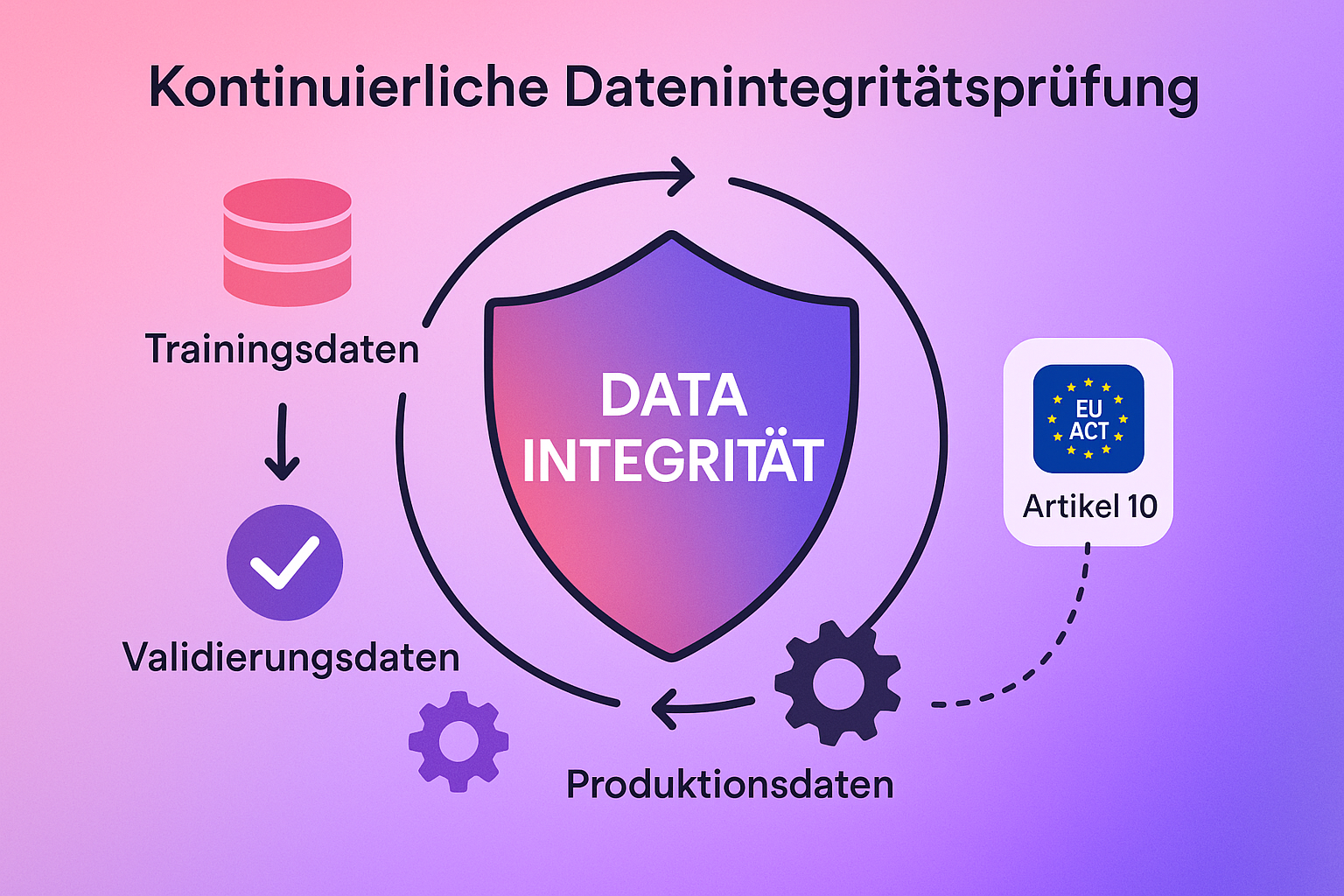
Klassische Audits verlassen sich oft auf Stichproben zu einem bestimmten Zeitpunkt. In modernen CI/CD-Pipelines (Continuous Integration/Continuous Deployment), wo KI-Modelle ständig neu trainiert werden, ist eine einmalige Prüfung wertlos. Die Integritätsprüfung muss, genau wie die Softwareentwicklung, kontinuierlich erfolgen.
Wer hierfür keine technische Lösung parat hat, riskiert nicht nur Bußgelder, sondern auch die Sicherheit seines Systems. Wer tiefer in die regulatorischen Grundlagen eintauchen möchte, findet in unserem Überblick zum EU AI Act weitere Details zu den gesetzlichen Rahmenbedingungen.
Wie stellen wir also sicher, dass die Daten, die wir heute nutzen, dieselben sind wie gestern? Die Antwort liegt in einer Kombination aus kryptographischen Methoden und modernem Datenmanagement.
Der effektivste Weg, Datenintegrität zu prüfen, ist das Hashing. Dabei wird für jeden Datensatz (oder Chunks von Daten) ein eindeutiger Hash-Wert (ein digitaler Fingerabdruck) erstellt.
Für große Datenmengen nutzen fortschrittliche Frameworks sogenannte Merkle Trees. Diese ermöglichen es, die Integrität riesiger Datenbanken zu überprüfen, ohne jedes Mal alle Daten komplett lesen zu müssen.
Um Manipulationen vorzubeugen, sollten Rohdaten und Logs in einem „Write Once, Read Many“ (WORM) Speicher abgelegt werden. Hier kommt das Konzept des immutable backup ins Spiel. Was im Kontext der Cybersicherheit gegen Ransomware schützt, dient im KI-Kontext als Beweis der Unverfälschtheit Ihrer Trainingsbasis gegenüber Auditoren.
Datenintegrität bedeutet auch Kontext. Tools zur Data Lineage zeichnen automatisch auf:
Dies ist entscheidend, um die allgemeine AI-Datenqualität nicht nur zu behaupten, sondern den gesamten Lebenszyklus transparent zu machen.
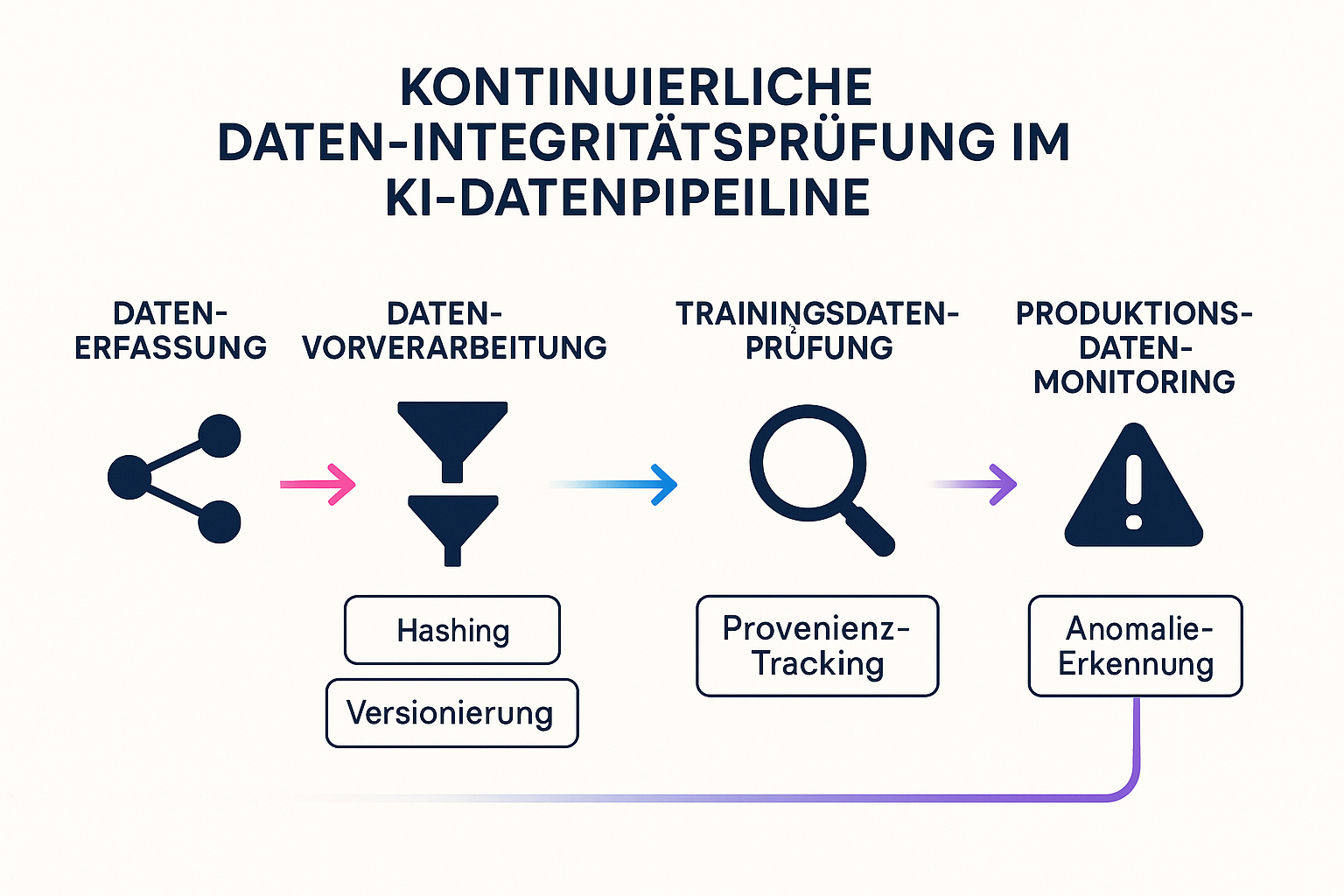
Die größte Hürde für Unternehmen ist oft die operative Umsetzung. Niemand möchte manuelle Excel-Listen führen, um Datenhashes zu vergleichen. Die Lösung liegt in der Automatisierung innerhalb der MLOps-Pipeline.
In einer robusten Architektur durchlaufen Daten verschiedene "Tore". Bevor Daten vom "Ingestion Layer" (Eingang) in den "Training Layer" übergehen, prüft ein automatisiertes Skript:
Schlägt einer dieser Tests fehl, wird die Pipeline gestoppt. Das verhindert, dass ein KI-Modell auf korrumpierten Daten lernt – ein Fehler, der später nur schwer zu korrigieren ist. Dies ist besonders wichtig, wenn Sie verschiedene EU AI Act Risikoklassen in Ihrem Portfolio verwalten, da Hochrisiko-Systeme hier keinerlei Toleranz erlauben.
Datenintegrität ist untrennbar mit der allgemeinen Informationssicherheit verbunden. Sie können die besten Hashing-Algorithmen verwenden, aber wenn die Zugriffskontrollen auf Ihre Datenbanken lax sind, ist das System verwundbar.
Ein ganzheitliches Konzept für Informationssicherheit (nach ISO 27001 oder TISAX) bildet das organisatorische Dach. Es regelt, wer überhaupt Schreibrechte auf Trainingsdaten hat und stellt sicher, dass Manipulationen nicht nur technisch erkannt, sondern auch organisatorisch erschwert werden.
Um die Lücke zwischen Theorie und Praxis zu schließen, hilft ein Blick auf die konkreten technischen Anforderungen. Ein funktionierendes Qualitätsmanagementsystem (QMS) für KI muss diese Punkte abdecken.
Die Integration dieser Punkte in Ihr Qualitätsmanagement und ISO 9001 Compliance ist der sicherste Weg, um Audits entspannt entgegenzusehen.
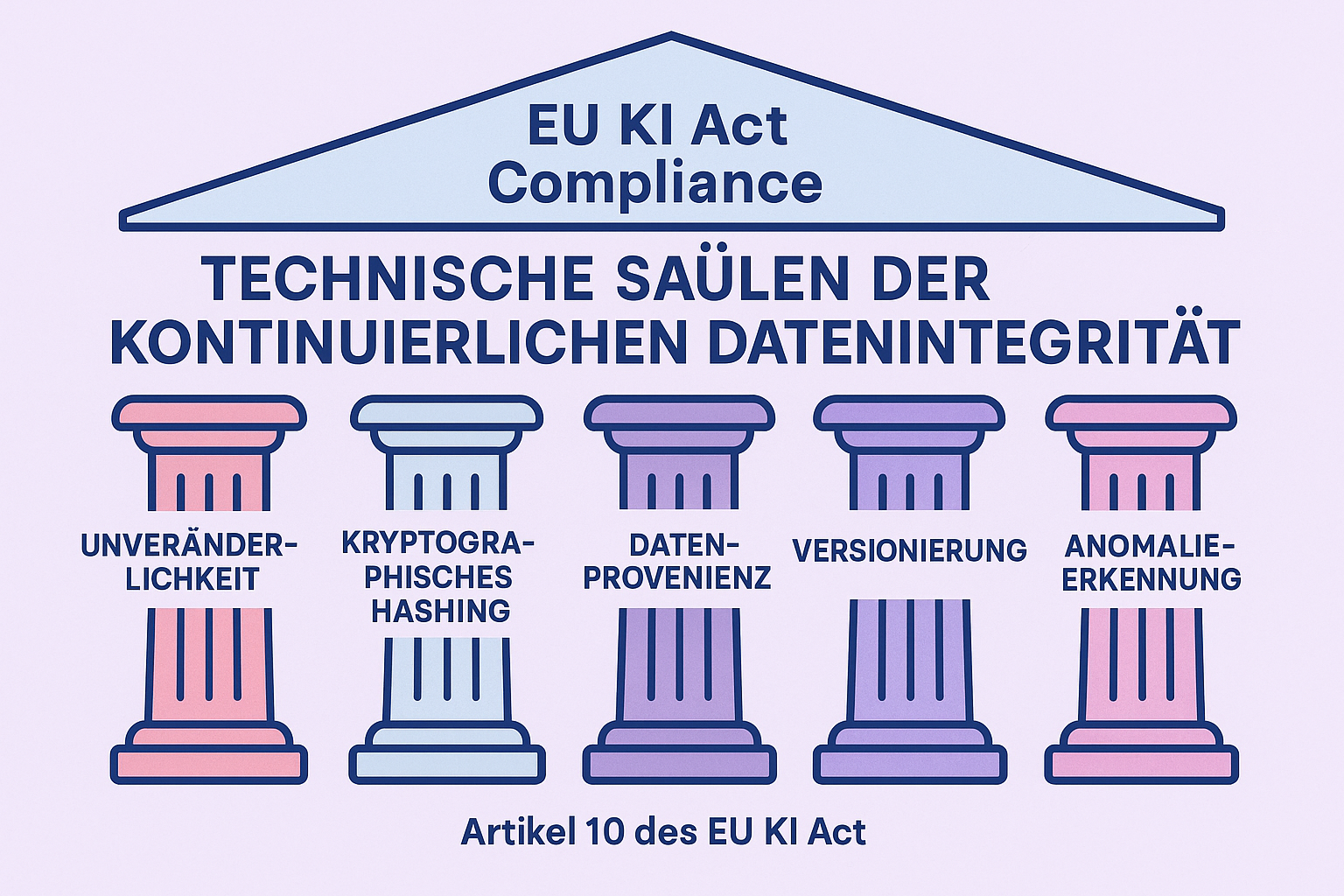
Die Anforderungen des EU AI Act zur Datenintegrität mögen auf den ersten Blick wie eine bürokratische Hürde wirken. Doch technisch betrachtet zwingen sie Unternehmen zu etwas sehr Sinnvollem: Hygiene in der Datenhaltung.
Eine kontinuierliche Datenintegritätsprüfung schützt Sie nicht nur vor Bußgeldern. Sie schützt Ihr wertvollstes Asset – Ihr KI-Modell – vor schleichender Verschlechterung und Manipulation. Indem Sie technische Frameworks nutzen, die Sicherheit und Compliance automatisieren, verwandeln Sie eine gesetzliche Pflicht in einen Wettbewerbsvorteil: Vertrauenswürdige KI, auf die sich Ihre Kunden verlassen können.
Nein, die strengen Anforderungen des Artikel 10 richten sich primär an Hochrisiko-KI-Systeme. Für Systeme mit geringem Risiko (z.B. Spam-Filter) gelten weniger strikte Transparenzpflichten. Es ist jedoch eine Best Practice, Integritätsprüfungen generell zu etablieren, um die Modellleistung zu sichern. Mehr zu den Kategorien finden Sie in unserer Übersicht zur Klassifizierung von Hochrisiko KI.
Data Drift ist ein natürliches Phänomen, bei dem sich die Daten in der realen Welt langsam ändern (z.B. ändert sich das Kaufverhalten von Kunden).Integritätsverlust bedeutet, dass die Daten technisch verändert, beschädigt oder manipuliert wurden. Die kontinuierliche Prüfung muss beides unterscheiden können.
Theoretisch ja, praktisch nein. Bei den Datenmengen, die für modernes KI-Training nötig sind, ist eine manuelle Überprüfung fehleranfällig und unwirtschaftlich. Automatisierte Compliance-Tools sind hier der Industriestandard.
Als Jurist mit langjähriger Erfahrung als Anwalt für Datenschutz und IT-Recht kennt Niklas die Antwort auf so gut wie jede Frage im Bereich der digitalen Compliance. Er war in der Vergangenheit unter anderem für Taylor Wessing und Amazon tätig. Als Gründer und Geschäftsführer von SECJUR, lässt Niklas sein Wissen vor allem in die Produktentwicklung unserer Compliance-Automatisierungsplattform einfließen.
SECJUR steht für eine Welt, in der Unternehmen immer compliant sind, aber nie an Compliance denken müssen. Mit dem Digital Compliance Office automatisieren Unternehmen aufwändige Arbeitsschritte und erlangen Compliance-Standards wie DSGVO, ISO 27001 oder TISAX® bis zu 50% schneller.
Automatisieren Sie Ihre Compliance Prozesse mit dem Digital Compliance Office

Die häufigsten Fragen zum Thema

Videokonferenzsysteme sind heutzutage für viele Unternehmen unverzichtbar. Doch bei der Nutzung solcher Systeme sollten Datenschutzaspekte nicht außer Acht gelassen werden. Schließlich werden bei Videokonferenzen zahlreiche personenbezogene Daten verarbeitet, weshalb spezifische datenschutzrechtliche Anforderungen beachtet werden müssen. In unserem neuesten Blogartikel präsentieren wir Ihnen fünf wichtige DSGVO-To-Dos, um Ihre Datenschutzmaßnahmen während Videocalls zu verbessern. Lesen Sie jetzt mehr!

Viele Unternehmen sehen Informationssicherheit noch immer als reine IT-Aufgabe, doch ISO 27001 A.5.2 macht klar: Sicherheit ist ein Teamsport. Erfahren Sie, wie Sie Rollen und Verantwortlichkeiten für alle Abteilungen praxisnah definieren und verankern. Dieser Leitfaden zeigt, wie Sie Ihre Mitarbeitenden zur stärksten Verteidigungslinie gegen Cyberangriffe machen.

Ein effektives ISMS ist entscheidend, um sensible Informationen in der digitalen Geschäftswelt zu schützen. Ein ISMS Audit ist eine systematische Bewertung des ISMS, das sicherstellen will, dass das ISMS den relevanten Standards entspricht. ISMS Audits können für Unternehmen Herausforderungen darstellen, insbesondere aufgrund der komplexen Anforderungen an die Unternehmen. In diesem Artikel stellen wir die verschiedenen Audittypen, den Ablauf und die Erfolgsfaktoren von ISMS Audits vor.
